
Códigos de barras 1D
Los primeros códigos de barras utilizados en todo el mundo fueron los códigos de barras 1D (unidimensionales). Estos códigos lineales solo contienen datos alfanuméricos. Cada uno de los caracteres en el código representa algo diferente sobre el producto y una base de datos brinda la información sobre que significa cada carácter.
En la mayoría de los casos la mayoría de los códigos de barra 1D se leen de izquierda a derecha. El ancho de los espacios y las barras se relacionan con un carácter específico en el código de barras. Una zona muda o margen es el espacio en blanco a la izquierda y la derecha del código de barra, que ayudan a que el lector pueda localizar el código de barras.
Como regla general, los márgenes deben ser, al menos, entre siete a diez veces más anchos que el ancho de la barra más delgada del código de barras.
Todas las demás barras del código se basan en una relación de la anchura de la barra más angosta. Por ejemplo, 2.1, 3.1 y 2.5.1 son relaciones comunes que describen el ancho de los espacios en blanco y las barras negras en base al punto de inicio de la barra negra más delgada. Algunos de los códigos de barras cuentan con un patrón de protección, este patrón de protección se localiza en la parte inicial y final del código de barras. Este patrón le indica al lector de código de barras donde comienza y termina el código de barras.
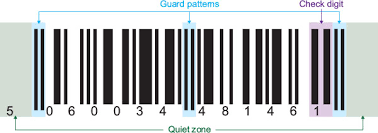
La mayoría de estos códigos de barras incluyen un dígito de comprobación como parte de su estándar. El dígito de comprobación se utiliza para verificar que el código se encuentra completo, que no se encuentra dañado y tampoco le falta información.
Códigos de barras 2D
A diferencia de los códigos de barras 1D, los códigos 2D (bidimensionales) contienen información tanto en forma horizontal como vertical, lo que les permite almacenar mucha más información. Por ejemplo, un único código 2D puede almacenar hasta 3,116 caracteres numéricos o 2,335 caracteres alfanuméricos, en comparación con los 39 caracteres que pueden almacenar un código 39.
Este tipo de códigos cuentan con corrección de errores incorporada, similar a los dígitos de comprobación de algunos códigos 1D, que elimina efectivamente los errores de lectura.

Dentro de un código Data Matrix 2D, los datos suelen codificarse tres veces, lo que aumenta significativamente las probabilidades de que el código se lea correctamente.
Mientras que los códigos 1D tienen zonas mudas y patrones de protección para identificar dónde inicia y termina el código, un código 2D tiene una zona muda, un patrón de sincronización y un patrón de ubicación. El patrón de sincronización es el patrón en forma de L que se encuentra ubicado alrededor del borde exterior de dos lados del código 2D. Esto se utiliza para poder asegurar una orientación correcta durante la decodificación





